Test Management
Software testing lessons we can learn from edge cases
What we can learn from strange edge cases — the unforeseen problems that happen when an app is operating at the relative extreme of its normal parameters.

Nick Moore

On February 29, 2024, something funny happened; well, many funny things happened. February 29 was Leap Day, and though the day itself is predictable (it happens roughly every four years), it’s infrequent enough that not everyone builds software with Leap Day in mind.
So, what happened?
- In Sweden, the card payments system at ICA, the country’s biggest supermarket chain, went down.
- In Colombia, the ticket printing system at Airline Avianca, the country’s biggest airline, printed tickets as 3/1 instead of 2/29.
- In New Zealand, card payment machines at numerous gas station chains, including Allied Petroleum, Gull, Z, and Waitomo, all crashed.
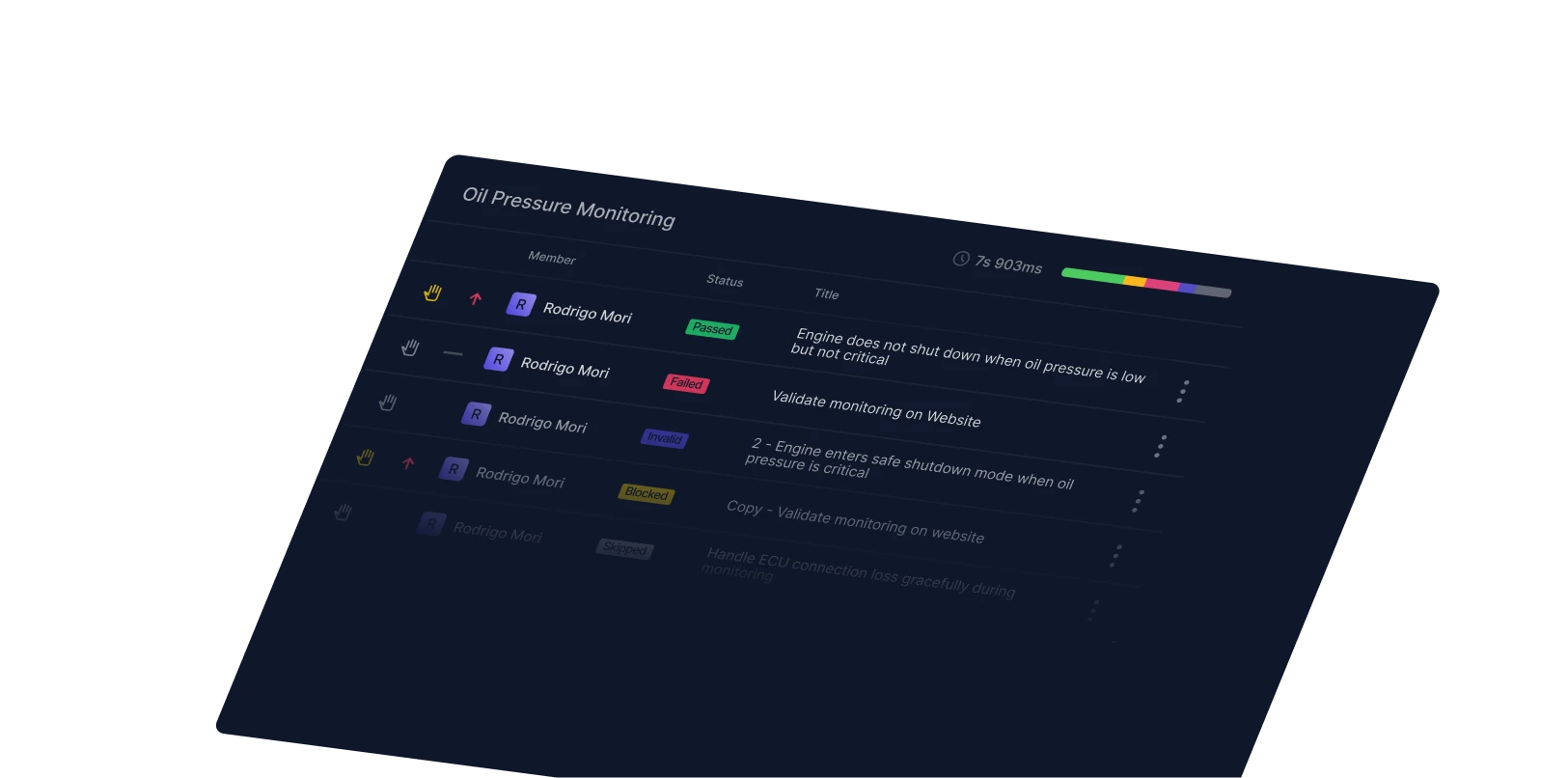
One of the most notable examples was from EA Sports WRC, a racing game released by (you guessed it) EA Sports. The game was released in November 2023 but became unplayable on Leap Day 2024. An official EA Help account on X (formerly Twitter) recommended players dive into the system settings and manually switch the date to March 1, 2024, just to make the game playable again.
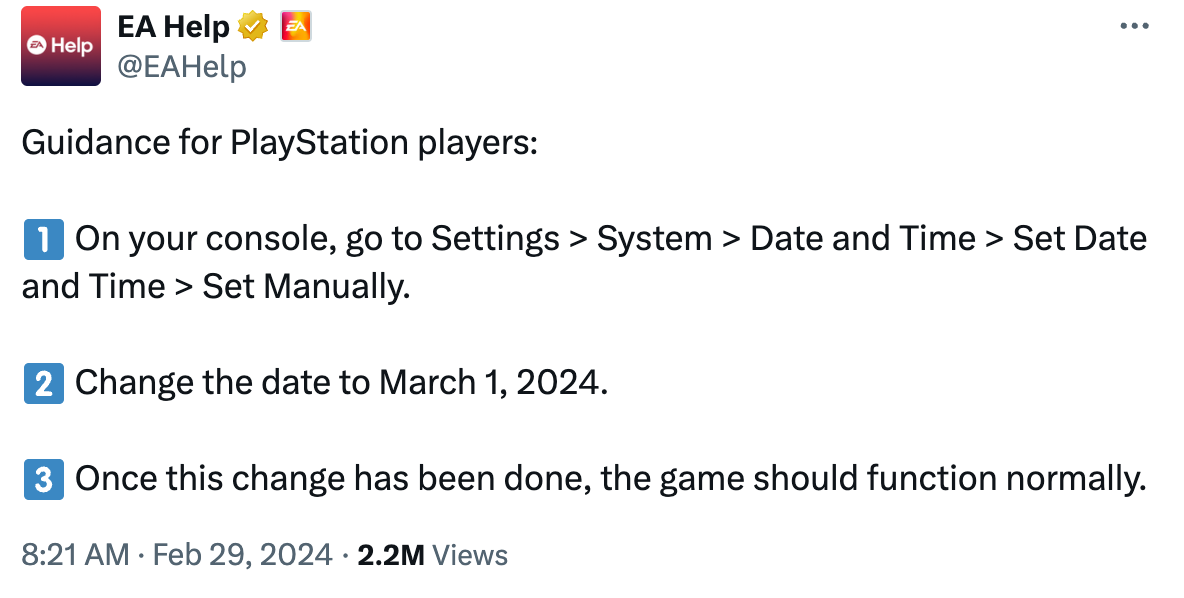
As Gergely Orosz notes, where he’s gathered numerous Leap Day fiasco examples, “This crash is notable, given the games industry invests more heavily than most other companies into quality assurance and thorough testing of the games. It is further proof of how easy it is to forget about an edge case that comes up just five months after the release of the game.”
Edge cases are the bane of every developer, tester, and quality assurance engineer. Deep in testing, it can often feel like all you’re doing is looking for edge cases, finding them, and figuring out ways to account for them.
In this article, we’re going to dig into edge cases: What are they? How can you find them? How can you fix them? Should you? We can only promise two things: Fixing edge cases will improve your code, but you’ll never catch them all.
What is an edge case?
Edge cases are unforeseen problems that happen when an application is operating (or being made to operate) at the relative extreme of its normal operating parameters.
Leap Years don’t appear “extreme” at first, for example, but they are: For almost every year long period, there are 365 days right in a row — no problem. Except when there is.
The core cause of edge cases is core to software itself: Computer software is unerringly logical, and if you tell a computer to do something (i.e., program it), then it will do it. Half or more of programming is articulating how to make computers do one thing and not the million other things they could potentially do, given your instructions.
Almost every developer, when they were first learning how to program, likely accidentally made an infinite loop, for example.
birds = 1
fish = 2
while birds + fish > 1 do
birds = 3 - birds
fish = 3 - fish
end
There isn’t a bug in this pseudocode or a flaw in how the computer interprets it. The computer, loyal as anything can be, will listen to you exactly. Without a terminating condition, it will just loop endlessly until you make it stop.
Edge cases follow the same logic but are much more subtle. For the most part, in 99.999% of cases even, your application is working just fine. But someone somewhere will use your software in a way, or context, or sequence you didn’t predict, and it will break.
If you’re developing a small project, this might not be a big deal. But if you’re trying to make anything business-critical, you need to proactively consider user behavior and look for edge cases and address them before putting anything in production.
Of course, a natural question arises: How can you find something that’s, by definition, outside the scope of normal use cases?
How are edge cases discovered?
Many edge cases will naturally occur to developers as they work. If you’re building a website for a modern browser, for example, it’s pretty intuitive that some amount of users might try to access it from a different browser or from an older, out-of-date version.
But as developers work, a focus on the “happy path” can make edge cases almost invisible. Developers can and should try to maintain awareness of edge cases as they build but will inevitably need to take a step back and proactively look for edge cases via analysis and software testing.
Equivalence partitioning
In equivalence partitioning, testers divide a collection of possible test conditions into partitions they can test separately. Equivalence partitioning is especially useful when there’s a large number of test cases and testers need to reduce that number into manageable chunks. By dividing input variables into equivalent partitions, testers can reduce the overall number of test cases while still catching edge cases.
If a web form calls for a user’s age, for example, a tester using equivalence partitioning might subdivide the possible input variables users might put into an age form by collecting ages that are invalid (too low), valid (humanly possible), and invalid (too high). Then, instead of testing every possible value, they can test input values that represent those partitions.
Boundary value analysis
In boundary value analysis, testers focus on testing the extreme boundaries around input variables. Each of these extremes is on either end of the spectrum, such as start and end, lower and upper, and maximum and minimum.
As in equivalence partitioning, this technique comes in especially handy when it would otherwise be too laborious to cover every possible test case. Using the previous example, a tester using boundary value analysis might first do equivalence partitioning and then test the boundaries between each partition: slightly too young, just barely old enough, right in the middle, almost too old, and far too old.
UI tests and E2E tests
In previous articles, we’ve covered the test pyramid and focused on its peak: end-to-end tests (sometimes called UI tests). E2E tests can be difficult to write and run, but edge cases are a great reason to learn how to do them efficiently.
Orosz, for example, formerly an engineering manager at Uber, explains, “Many larger teams are hesitant to use too many UI or end-to-end tests because of their spotty reliability. They’re also time-consuming to write, and because they’re slow to run, some teams don’t execute them on each pull request.”
Nevertheless, Orosz strongly recommends UI tests: “A stable and relatively quick-to-execute UI test suite is a major competitive advantage because it comes closest to simulating people actually using your app.” By simulating how users use your application, you can better notice and test edge cases.
Orosz also recommends running UI tests that communicate with server endpoints (he calls these E2E tests, but again, definitions vary here) because some scenarios, especially the edge cases, are hard to simulate.
When should you fix an edge case?
It’s tempting to assume that all edge cases should be found and fixed — no exceptions. Unfortunately, the practical realities of software development require otherwise.
From a business perspective, applications need to be shipped. While you don’t want to ship something noticeably shoddy, we live in an era where patches can be made rapidly available if and when the need arises.
But even from a testing perspective, finding and fixing all edge cases is simply impossible. In equivalence partitioning, for example, testers sacrifice comprehensiveness by testing only representative inputs. As you find edge cases, look to these reasons to help you determine whether you should address them and how urgently.
Do: When it affects a large number of users
The most obvious reason to fix an edge case is also the most compelling: If you find an edge case that is likely to either affect a large number of users or to affect a significant number of them severely, fixing that edge case should be a high priority.
The obviousness here, however, belies how not-obvious an edge case can really be. For example, many web developers assume most users can load Javascript. From afar, this might seem true enough, but if you look at all the reasons why not, many small edge cases can coalesce into something bigger.
Consider, as a demonstration, Stuart Langridge’s Everyone has JavaScript, right? flowchart.

Source: Everyone has JavaScript, right? flowchart.
You need to be able to check your assumptions to really catch the “obvious” big edge cases.
Do: When it’s a simple fix
The second most obvious and most compelling reason to address an edge case is when it’s a simple fix. At a certain point, even a marginal, low-impact edge case is worth addressing if it doesn’t take much time or effort.
Do: When an edge case creates an exploit
Sometimes, an edge case transforms from a small, almost unnoticeable issue into a major security issue just by its discovery and dissemination. In the tweet below, for example, a rogue user finds an edge case a Discord developer or tester might never have come across — why would they? But once a user, malicious or not, finds the edge case and tells others — particularly in a public forum like social media — addressing it becomes a high priority.
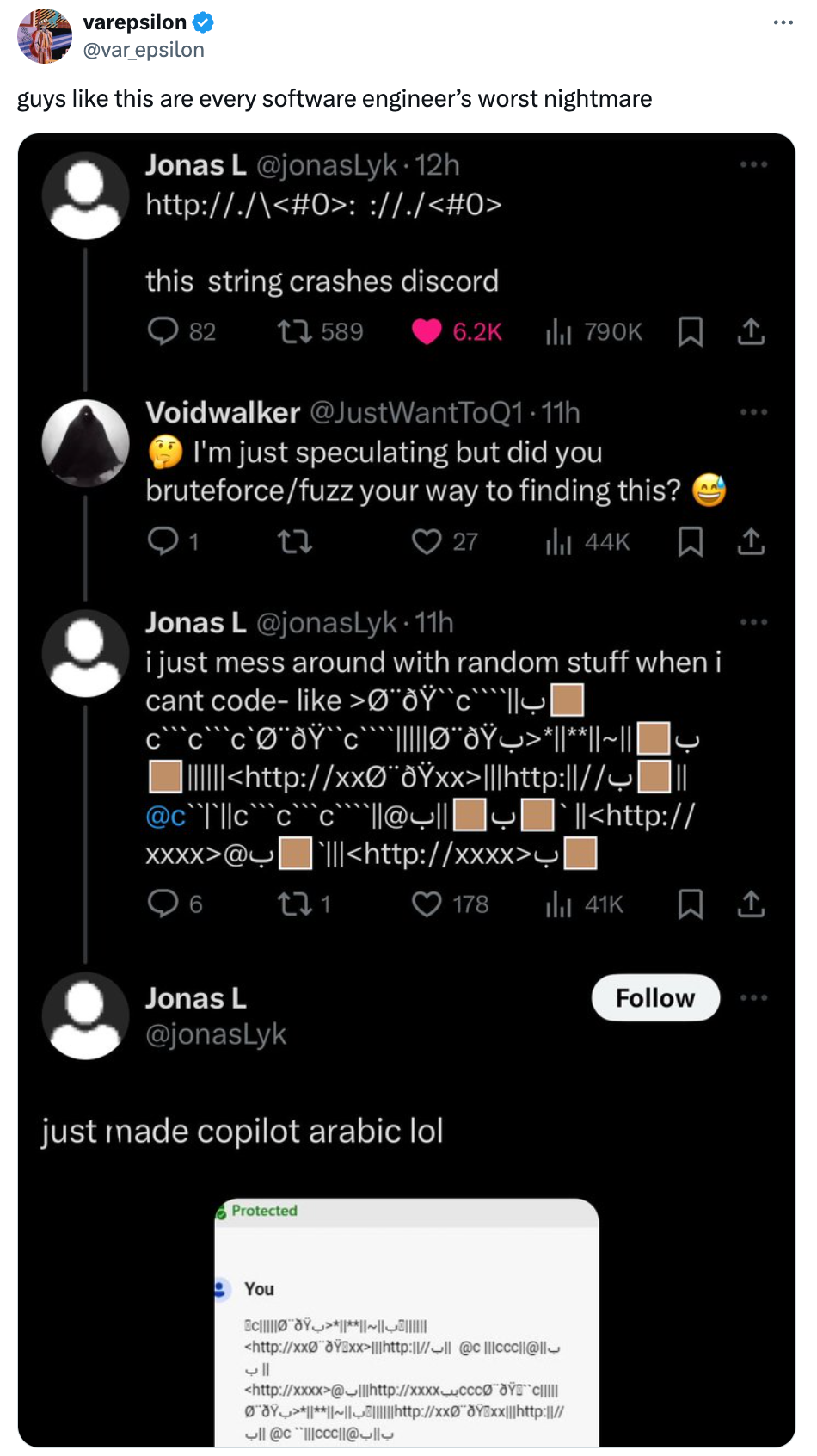
Of course, in this example, we clearly have a troll having fun. Truly malicious actors will look for edge cases that lead to vulnerabilities and not tell you until they’ve exploited you.
Don’t: When you’re working from the wrong abstraction
Swizec Teller, a technical lead at Tia, shares an experience that most developers will recognize: “You know how sometimes you're building a thing and everything keeps going wrong? Edge case after edge case, workaround after workaround. Things are just hard.”
When you’re building (or testing) and around every corner is an edge case, it’s tempting to fix them one by one and keep moving on. But at a certain point, as Teller says, you might discover you just have the wrong abstraction.
“A good abstraction,” Teller writes, “hides details and makes them unimportant. You call a function, it does the thing, and you don't care how. The opposite of lasagna or minestrone code.
A bad abstraction ... that feels like work.” And work, in situations like these, often means a seemingly endless number of edge cases.
At a certain point, the number of edge cases you’re encountering means you should stop thinking about fixing edge cases and start thinking about a different approach.
Don’t: When there’s a bad tradeoff
A common mistake developers and testers make early in their careers (though it can happen to anyone) is to assume every edge case is worth addressing — no matter how much time it takes.
Hillel Wayne, a software development consultant, calls this “edge case poisoning.” To demonstrate the idea, he walks through the requirements-writing process while developing a data model for a cookbook. Edge cases abound! A seemingly simple project becomes complex as you consider how different recipes can be formatted, how some can include sub-recipes, special equipment, and different ways of wording ingredients.

Worse, Wayne points out, is that fixing an edge case for one user can conflict with another user’s needs. “Alice needs recipes with inedibles, Barry needs recipes with optionals, and everybody else needs neither. Alice is ‘punishing’ everybody else with her edge case. They have a more complicated API because of her. In turn, she's ‘punished’ by Barry's edge case.”
Wayne writes that edge case poisoning is “almost impossible to avoid because anything dealing with the real world is going to have tons and tons of edge cases.” With this in mind, every edge case needs to be weighed against the effort it will take to fix it and the tradeoff of addressing it. Sometimes, it’s just not worth it.
Edge case examples and lessons
Software development is a wicked problem, but many parts of development are fairly predictable — especially for experienced developers and testers. As you build and test these more predictable parts, however, the wickedness gets pushed to the edges, meaning edge cases are often almost entirely unpredictable and impossible to scope.
Below, we’ve gathered a short tour of some of the worst, weirdest, and most interesting examples of edge cases. We’ve extracted a few lessons, but the broader takeaway is that your edge case will likely never be someone else’s (and vice versa).
1. Performance at Glitch
The edge case: Mads Hartmann, an engineering manager at Glitch, chronicles the discovery of a performance problem and the multi-month journey to fix it. “For months, we’d been seeing a steep increase in the number of projects being built on Glitch, and more and more traffic headed to them. We struggled to keep up. What had started as performance edge cases had become commonplace. Many unknown unknowns had become known unknowns.”
The lesson: The entire timeline is worth reading, but the high-level takeaway is that small efforts can turn into big efforts, and small problems can turn into big problems. By the end, Glitch had built a whole new observability system – a journey that Harmann said “will benefit our systems and our users.”
2. Text classification at Humane
The edge case: Humane, which recently released its first product, the AI Pin, encountered a wave of bad reviews. In one, an editor from The Verge asked the Pin to play the song Texas Hold Em by Beyoncé, and the Pin stumbled over the accent in Beyoncé’s name (first reciting “BeyoncU+00E9”) and then sharing aloud the instructions it was supposed to send to Humane’s backend.
The lesson: Though the Pin has been criticized, this edge case isn’t as embarrassing as it first appears. For example, Julien Voisin gathered a long list of edge cases music classification can present († from Justice, ★ from David Bowie, () from Sigur Rós, and on and on), and Karol Wrótniak gathered a list of edge cases for text more broadly (as a sample: “What is the lowercase of a Latin capital letter i with tilde Ĩ? As you may have guessed, the answer is not so trivial”). These are age-old types of potential edge cases that have haunted developers and testers for decades. Watch for them, yes, but know that they’re countless, too.
3. Client/server connection at Uber
The edge case: Bozhidar Bozhanov, formerly the founder and CEO of LogSentinel and now a member of the National Assembly of the Republic of Bulgaria (don’t let anyone tell you you can’t pivot your career), wrote in 2014 about an interesting edge case he found while using Uber. At the time, he was trying Uber for the first time, so he requested a ride, got it, and then was confused when the driver only took him a short distance. Bozhanov couldn’t make a correction via the app, however, because he didn’t have mobile data. Shortly, he received a receipt that confirmed the strange, short ride.
The lesson: Bozhanov wrote about this experience not because it was a disaster but because he had experienced issues like these while developing and testing, too. Bozhanov has a few recommendations, such as ensuring your app holds a connection state and showing the user whether it’s connected or disconnected. “Your server should not rely on a 100% stable connection,” he adds. “And therefore disconnects should not trigger any business logic. In the above example with Uber, it might be that upon 30 seconds of unresponsive client app, the server decides the ride is over (e.g. I am trying to trick it).”
4. Cultural differences at FedEx (and beyond)
The edge case: In this Twitter thread, Foone Turing, a Python programmer, shares an edge case she stumbled upon in real life. A customer trying to ship a package to Brazil via FedEx was running into an issue with FedEx’s forms – their address had too many address lines, and the lines were too long, so the forms ran out of field length.
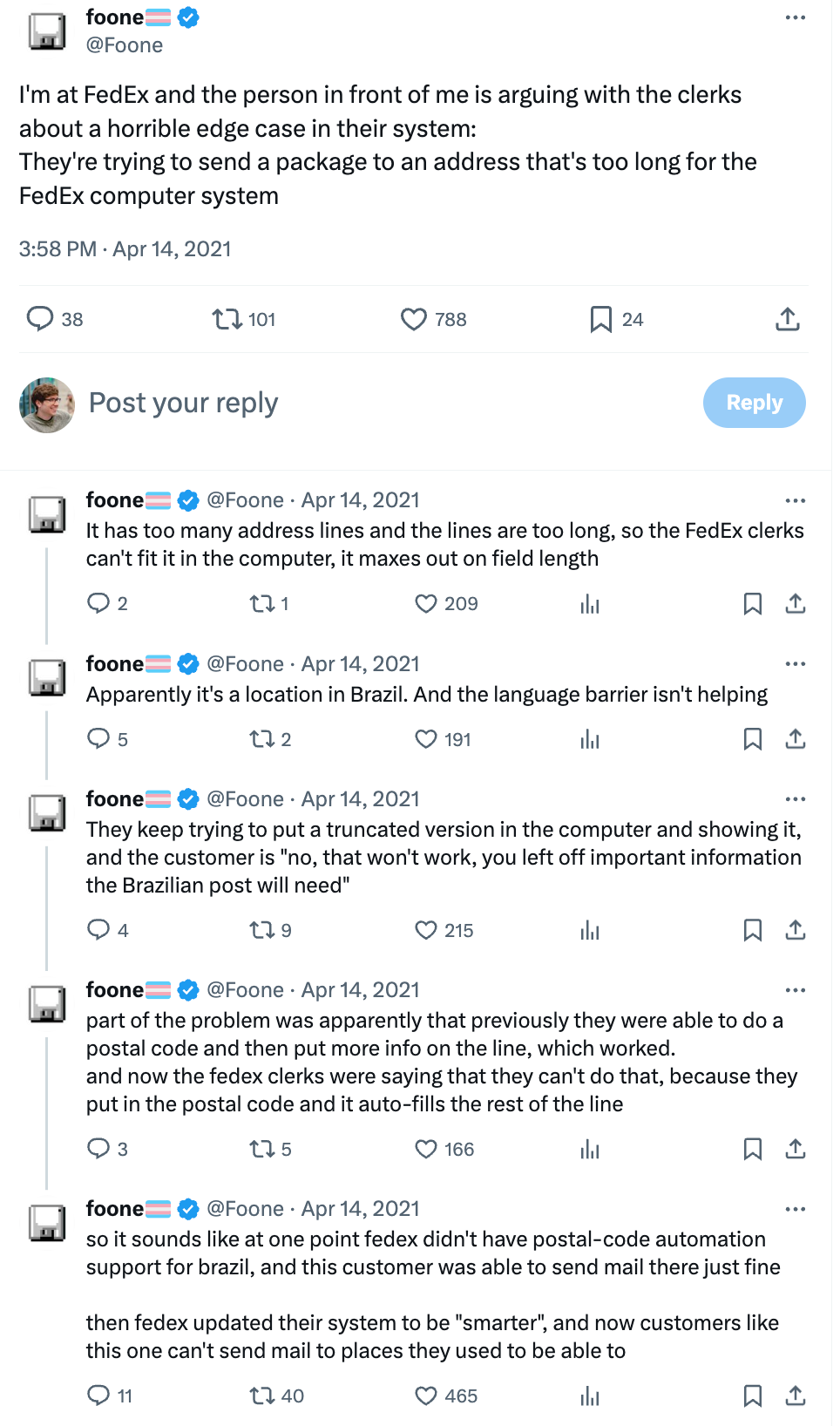
The lesson: At first glance, this isn’t an interesting edge case. As we said in a prior section on boundary value analysis, this kind of edge case is fairly predictable, and best practice testing can often find it. Similarly, and sadly, many companies also make the same essential mistake of not seeing an edge case because of cultural differences. What is interesting is Foone’s point in the last Tweet: “It sounds like at one point FedEx didn't have postal-code automation support for Brazil, and this customer was able to send mail there just fine. Then, FedEx updated their system to be ‘smarter,’ and now customers like this one can't send mail to places they used to be able to.” The lesson here, then, is that smarter isn’t always better and that testing for edge cases needs to be involved in every update.
5. Intentional misuse at Place Card Me
The edge case: Cory Zue, founder of SaaS Pegasus and Place Card Me, recommends that developers stop worrying about edge cases. There are limitations to this advice, but the edge case he shares is worth highlighting. When building Place Card Me, a tool that makes it easy to make printable place cards for weddings, he gave users thirty days to edit their cards. What happened after thirty days? Nothing! Zue writes, “I didn’t feel like building out all that logic so I just never bothered! What that means is that everyone who has ever used Place Card Me has received a lifetime supply of free place cards.”

The lesson: Zue uses this as an example of why you shouldn’t care about edge cases because only fifteen people in a year (from 1500 sales) actually abused the exploit. Zue writes, exemplifying what we wrote earlier about weighing tradeoffs, “In most cases, you can focus on intentional usage for a long time and you’ll save yourself a lot of time and energy [...] If they’re important enough to address they’ll make themselves known eventually.”
6. Infinite money glitch at Amazon
The edge case: Back in 2011, the Wall Street Journal profiled Jeff Bezos, and Bezos shared that, early into Amazon’s journey, there was an incredible edge case that’s astounding to think about now. "We found that customers could order a negative quantity of books,” Bezos said, “And we would credit their credit card with the price and, I assume, wait around for them to ship the books.”
The lesson: Amazon had two major things working for it here: It was a much smaller company at the time and the Internet, as a whole, was less sophisticated. If you were to release a product with the same edge case nowadays, the exploit would go viral on TikTok in minutes. That said, there’s still a classic lesson here for startups: When you’re just starting out, shipping and making mistakes is better than not shipping.
7. Y2K at… the world
The edge case: Y2K is perhaps the biggest edge case the world has ever seen and yet, it’s also its most underrated. To make a very long story short: There was concern among technologists and eventually panic across the world that a common dating shortcut (for example, using “99” instead of “1999”) would cause chaos as the year turned over to 2000. Companies and governments spent millions of dollars to create patches and workarounds (Gartner estimated the global costs to be between $300 billion and $600 billion).
The lesson: In the book Kill It with Fire: Manage Aging Computer Systems (and Future Proof Modern Ones), Marianne Bellotti uses Y2K as a way to demonstrate an edge case and bug-causing tendency programmers had then, still have today, and will likely have tomorrow. Y2K sends a lesson repeated by the persistence of COBOL and repeated every time someone replaces an old framework with a new one: “People who were programming room-sized mainframes in the 1960s never thought their code would last for decades, but we now know programs this old are still in production. By the time the year 2000 came around, that old software (and sometimes the machines that came with it) had not only not been retired but was also being maintained by technologists two or three generations divorced from its creation.” Software lasts a long time and sometimes, the sheer passage of time is the culprit behind an edge case.
Best practices are worst practices
In a previous article, I wrote about the test pyramid and its discontents, arguing at one point that “the test pyramid became a best practice, and best practices have their own gravitational pull.”
The same idea is true for edge cases, but even more severely. There are a few best practices for finding edge cases that truly are good, such as equivalence partitioning and boundary value analysis, but edge cases — by definition — push past your assumptions and best practices.
Edge cases are at the edge — of best practices, of your knowledge, of your expectations. Finding some is easy; finding all of them is impossible; and figuring out which to address and how will always be vexing.
As Leo Tolstoy wrote in the opening line of Anna Karenina, "Happy paths are all alike; every edge case is unhappy in its own way." (I think I got that right).
Related Posts
You might also like

Test Management
How much testing do we need? Economics of testing

Vitaly Sharovatov

Test Management
How to Write Test Cases

Torben Robertson
Test Management
Global Shared Parameters: Ending “Parameter Chaos” in Test Case Management

Berna Agar